Primer on Regular Expressions
In this post, I will try to give you a practical overview of Regular Expressions to teach you what they are, what they can be used for and a quick intro to how you can use them.

What are Regular Expressions even?
Regular Expressions (short Regexes) are Strings that work as a DSL (domain-specific language) to do some common tasks within other Strings. A DSL can also be subscribed as “a programming language within a programming language”.
In the case of Regexes, the outer programming language can be any programming language that supports the Stringtype, it just has to support Regexes. Nearly all popular programming languages support Regexes, which makes Regexes so useful to know. The inner language of Regexes consists of only String with some characters having a special meaning.
For example in the String ".*@.*\\.com" the . means "any character", the * means "any amount of <whatever precedes>", together .* means "any amount of any character". Then we have a non-special character @, then again .*followed by \\ which means "escape the next character and treat like a non-special character" so \\. together reads like a normal . character without the special meaning "any character". Lastly, there's com which is just a set of characters without any special meaning. Overall this Regex is a simple matcher for any email address ending with .com and containing a @ somewhere.
What can I do with the “Regular Expression DSL”?
irb to start an interactive Ruby shell to play around with the samples below.There are three main functions that any Regex string can be used with:
matches: Given a Regex and another String, this function checks if the given String "matches" the Regex. This means if there's "any" part within the given String that matches the specified Regex, it returnstrue, otherwise, it'sfalse. For example in Ruby (wherematchesis calledmatch?–?is part of the function name):
/.*@.*\\.com/.match?('harry.potter@hogwarts.co.uk') # => false /.*@.*\\.com/.match?('queenie.goldstein@ilvermorny.com') # => truecaptures: Given a Regex and another String, this function can read substrings out of the given text which matches marked portions of the given Regex. The portions in the Regex can be marked via(and). They are called "capture groups". For example in Ruby (wherecapturescan be accessed on theMatchobject):
/(.*)@(.*)\\.com/.match('queenie.goldstein@ilvermorny.com').captures # => ["queenie.goldstein", "ilvermorny"]replace: Given a Regex and a Template String, this function can automatically replace matches with a given String where even the capture groups can be referenced via$1,$2or in some languages also\\1,\\2, etc. For example in Ruby (wherereplaceis calledgsub):
'queenie.goldstein@ilvermorny.com'.gsub(/(.*)@(.*)\\.com/, '\\1@\\2.org') # => "queenie.goldstein@ilvermorny.org"What does the “Regular Expressions DSL” look like?
There’s plenty of useful “cheat sheets” for this with great examples:
Generally, there are 5 different kinds of DSL components to understand:
1. Character/Group Modifiers (e.g. *, +, {,}, ?)
The default “building” block of Regexes are characters. After each character, you can write a modifier that tells how many times the preceding character is matched. The following modifiers are available:
0 or 1 times: ? (example: a?b?c? matches all of a, ab, abc, bc, c)
1 time exactly:
No modifier (default)
0 to ♾️ times: * (example: a*bc matches bc, abc, aaabc)
1 to ♾️ times:+ (example: a+bc matches abc, aaabc but not bc)
X times exactly:{X} (example: a{3}bc matches aaabc but not aabc, aaaabc)
X to Y times:{X,Y} (example: a{2,5}bc matches aaaaabc, but not abc)
X to ♾️ times:{X,} (example: a{2,}bc matches aaaaaaaabc but not abc)
The same modifiers also work on Groups (e.g. (abc)+) (see below for groups).
Custom Sets (created with [ and ])
You can define custom sets of characters by listing them without any separator within brackets, e.g. for a set of the characters a, b, c and numbers 1, 2, 3 we would write [abc123]. This is then considered as "one character of this set", thus matching multiple of them need character modifiers as in [abc123]* or [abc123]{2,5}.
You can also use ^ at the beginning of a custom set to specify that you accept any character except the set you specified in the brackets, e.g. [^\\n] to accept any character except a newline.
Characters of which you know are ordered right after each other like numbers or the Alphabet you can also use ranges by putting a - in between, e.g. [a-zA-Z0-9].
[abc123]{3,} would not match a, b, c, ab, but would match 111, abc
Predefined Sets (\\s, \\S, \\d, \\D, \\w, \\W)
The following sets (simplified) are already pre-defined and can be used directly:
\\seffectively same as[ \\t\\n], reads "any whitespace character"\\Seffectively same as[^ \\t\\n], reads "any non-whitespace character"\\deffectively same as[0-9], reads "any digit"\\Deffectively same as[^0-9], reads "any non-digit"\\wsimilar to[a-zA-Z_0-9](includes Umlauts etc.), reads "any word character"\\Wsimilar to[^a-zA-Z_0-9]reads "any non-word character"
Groups (e.g. ( and ), (?<name> and ))
Groups could be thought of like “words” or “sentences”, they change the default building block, which is “character” for any modifier to a set of characters, or a “group”. For example, writing abc* reads "one time a, one times b and any number of times c". If you want to write "any number of times abc" you do this: (abc)*. The abc is then considered one group and the regex would match the whole string abcabcabc.
Groups also allow for specifying different options to choose from. For this, you write a group and separate the different words via a | like so: (abc|def) – this reads "either abc or def" and would match both 123abc123 and 456def456 but not adbecf.
These capture some sub-portions of a Regex and assign them a number or name which then can be used to reference them in code or in replacement template Strings. Typically capture groups like in (.*)@(.*).com are used then referenced back via \\1@\\2.com or $1@$2.com (depending on the language).
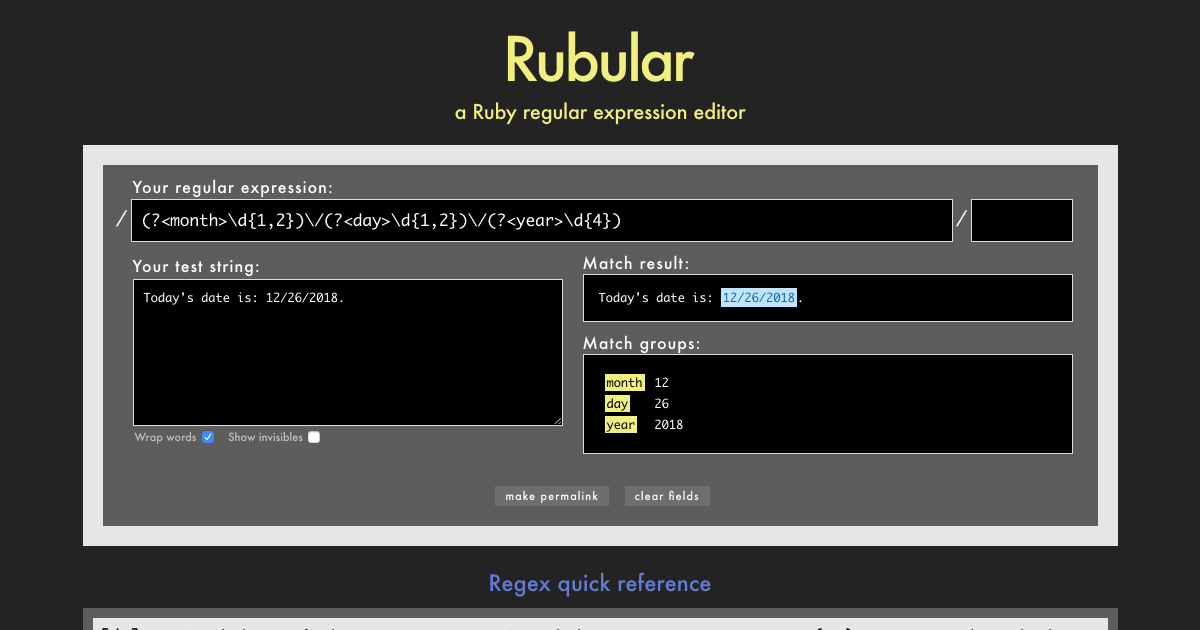
It’s also possible to give the groups names, e.g. (?<user>.*)@(?<domain>.*).com to reference back like in ${user}@${domain}.com, but these are advanced features which are implemented differently in different languages (and are missing in some).
Match Modifiers (e.g. \\A, \\z, ^, $, Lookaheads and Lookbehinds)
By default, a match for a Regex, like abc is done like a contains method. But you can also specify that the abc string needs to be at the beginning or end of a given string or of a line. For example, the ^ in ^abc makes sure only strings with abc at the beginning of a new line match. This will match def\\nabc but not defabc. The $ in abc$ makes sure there's a line-end after abc. Use \\A and \\z to match among the entire String (matching multiple lines).
Lookaheads & Lookbehinds are more of an advanced topic and useful mostly when you want to match that the beginning or end of your Regex does NOT match a given Regex. In most cases, Regexes with Lookaheads & Lookbehinds can be rewritten with Capture Groups, so you should try to write them as Capture Groups instead and only read about these if the other options don’t work as Lookaround are CPU-intensive operations and also kind of restricted (e.g. they don’t support most modifiers).
Here’s a good place to learn about them:
Common Quirks and validating new Regexes
One common thing to consider is that . in most languages does not match the newline character by default. But it can typically be turned on with an option, in Ruby by specifying the /m at the end which stands for "make dot match newlines".
Also note that in every language there are different characters that are reserved due to how Strings work in them, for example in Ruby / needs to be escaped with \\/, in Swift this escape is not needed but there you need to escape { and } with \\{ and \\}. These quirks are important to remember when copy & pasting Regexes written for other languages.
Generally, when writing a new Regex, I recommend using a website or tool with 3 features:
- An option to add a sample String to match against.
- A Regex cheat sheet visible right on the screen to look up things.
- A live matcher for the regex you write among the given sample String.
The site I’ve come to use here is this (runs Ruby in the background):
How can I use Regexes in my projects today?
There’s no need to wait until there’s a good opportunity to use Regexes, you can simply lint your projects using Regular expressions (including Auto-Correction support) via AnyLint:
 FlineDev
FlineDevA native Mac app that integrates with Xcode to help translate your app.
Get it now to save time during development & make localization easy.